About MELGYM
MELGYM is a Python tool designed to facilitate interactive control over MELCOR 1.8.6 simulations.
Every control feature in MELCOR is governed by Control Functions (CFs). However, MELCOR’s batch execution mode makes it difficult to interactively control and modify these functions under user-defined conditions. Control conditions must be defined a priori and often require chaining several CFs in a cumbersome and unintuitive way.
MELGYM enables the use of external, user-defined controllers—such as reinforcement learning agents or any other custom control algorithm.
Warning
The MELGEN and MELCOR executables are NOT INCLUDED in this package, as they are not freely distributable. MELGYM requires both executables, which must be located at the following paths: melgym/exec/MELGEN and melgym/exec/MELCOR.
Note
Access to MELGEN/MELCOR executables can be requested via the Sandia National Laboratories website.
How MELGYM works
MELGYM’s control system is based primarily on MELCOR’s restart capabilities. The restart mechanism in MELCOR involves:
Dumping the current simulation state into a restart file generated by MELGEN (i.e., creating a simulation checkpoint).
Performing a warm start from the last recorded state.
The MELGEN/MELCOR execution process
These two steps are performed periodically, according to the restart frequency specified in the MELCOR input configuration.
MELGYM introduces intermediate steps between restart dumps and warm starts, during which control functions or other user-defined components can be modified.
This allows simulations to be discretised into small time intervals, inserting intermediate steps where the model is continuously adapted.
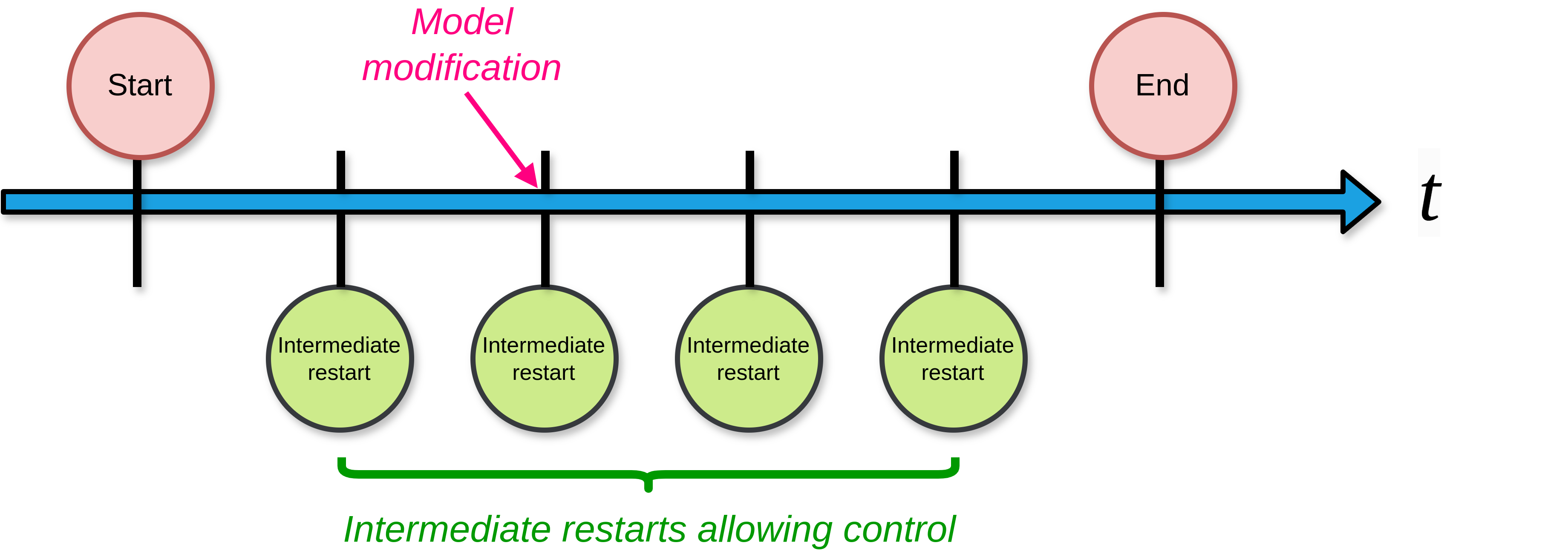
MELGYM introduces additional restart steps to enable fine-grained control over MELCOR elements
Note
The elements that MELGYM can modify depend on the overwrite capabilities of the MELCOR input. See the MELCOR Code Manual for more information.
Thus, MELGYM modifies the input model every few simulation cycles. After each warm start, the model resumes from the last saved state and continues under the new configuration defined by the external controller.
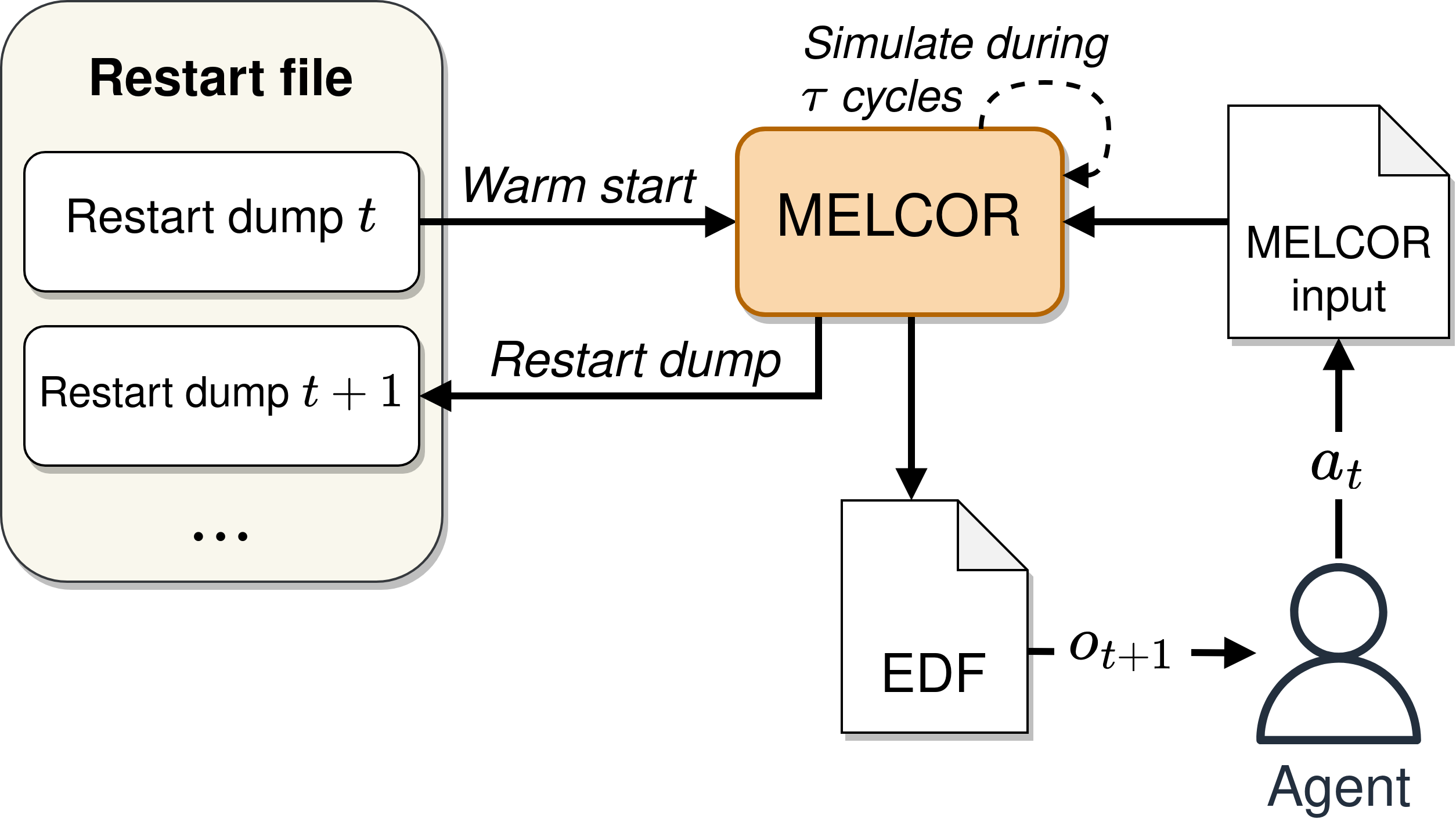
Control actions modify the MELCOR model just before each warm start
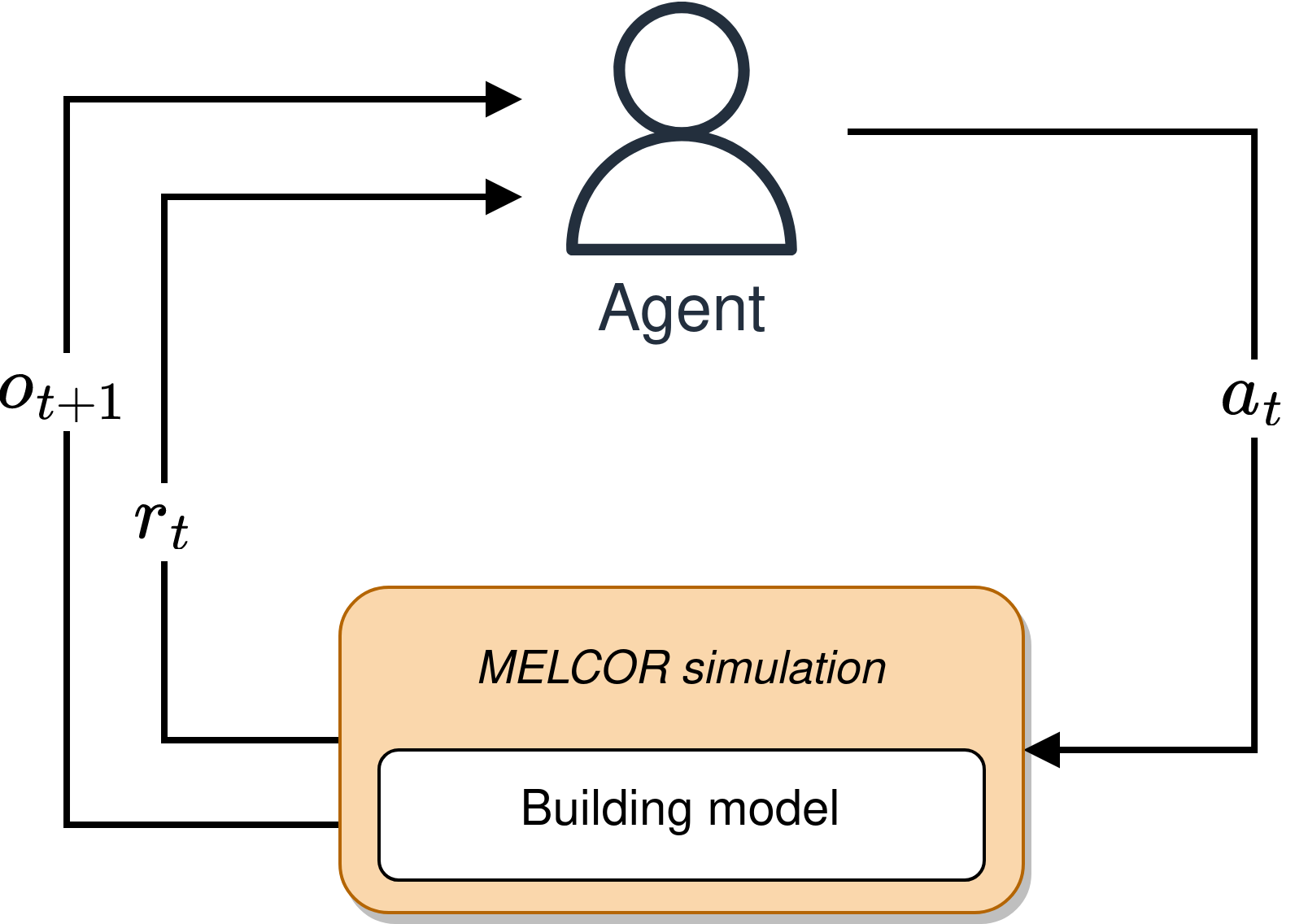
The following image summarizes the main functions and the low-level agent-environment interaction.
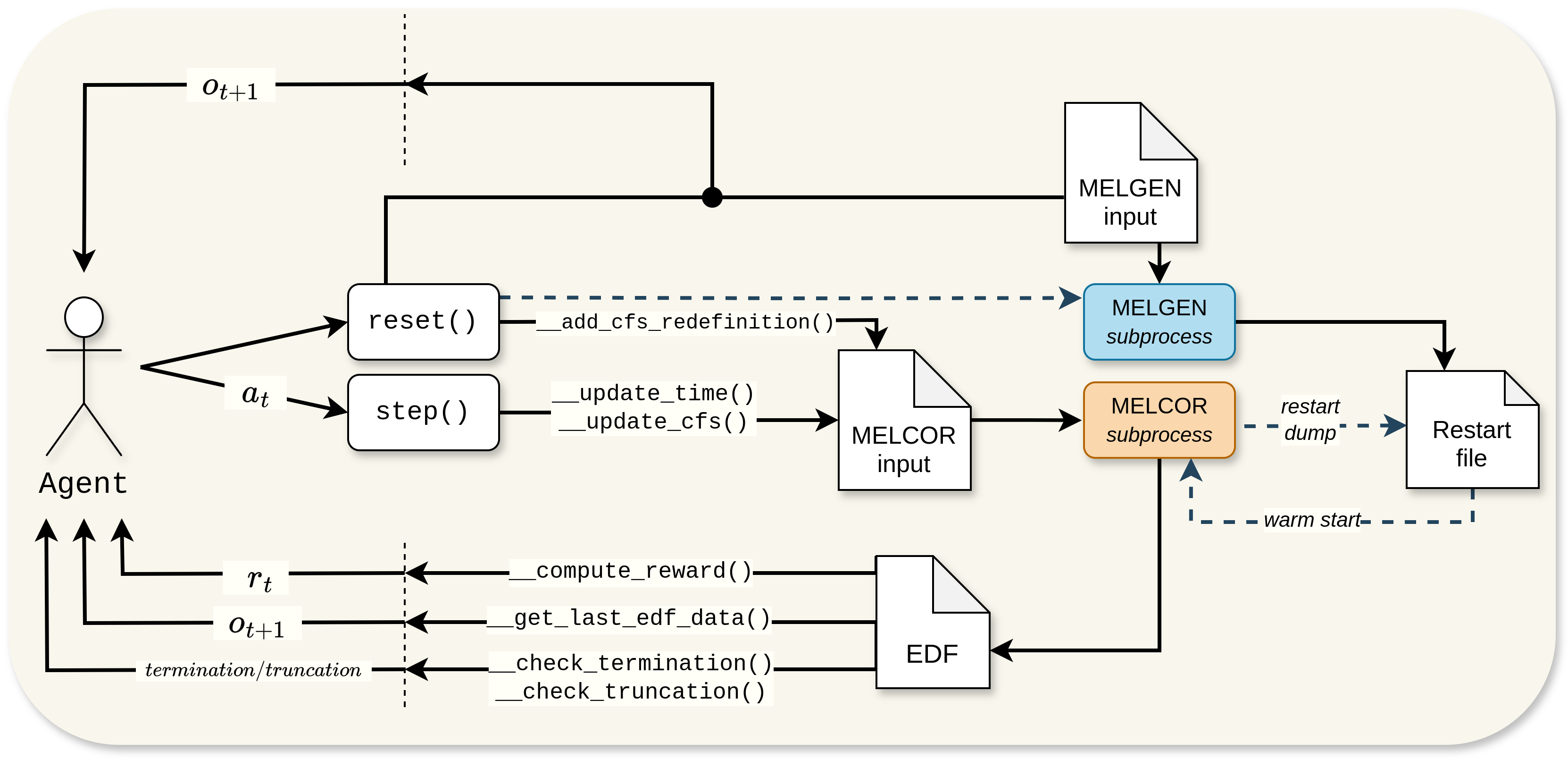
Low-level diagram of the agent–environment interaction loop
Environments
Every MELGYM environment inherits from the MelcorEnv class. To function properly, users should consider the following:
The CFs to be controlled must be specified when creating or registering the environment.
EDF records to be used as observations must be defined in the MELCOR input file.
Environment-specific parameters, such as the action space, must be set in the environment constructor.
Users must define the reward function and the termination/truncation conditions, as they are specific to each environment.
The EDF dump and restart frequencies must be consistent with the
control_horizon, and properly defined in the MELCOR input file.
Tip
Refer to API reference for a detailed definition of the MelcorEnv class and its methods.
Reinforcement learning integration
Formulation
Reinforcement Learning (RL) algorithms are particularly useful for learning control policies through interaction between an agent and a simulated environment.
In RL, an agent interacts with a dynamic process—called the environment—over a discrete sequence of time steps \(\mathcal{T} = \{0,1,2,...\}\). In MELGYM, the environment corresponds to a MELCOR simulation with which an agent interacts.
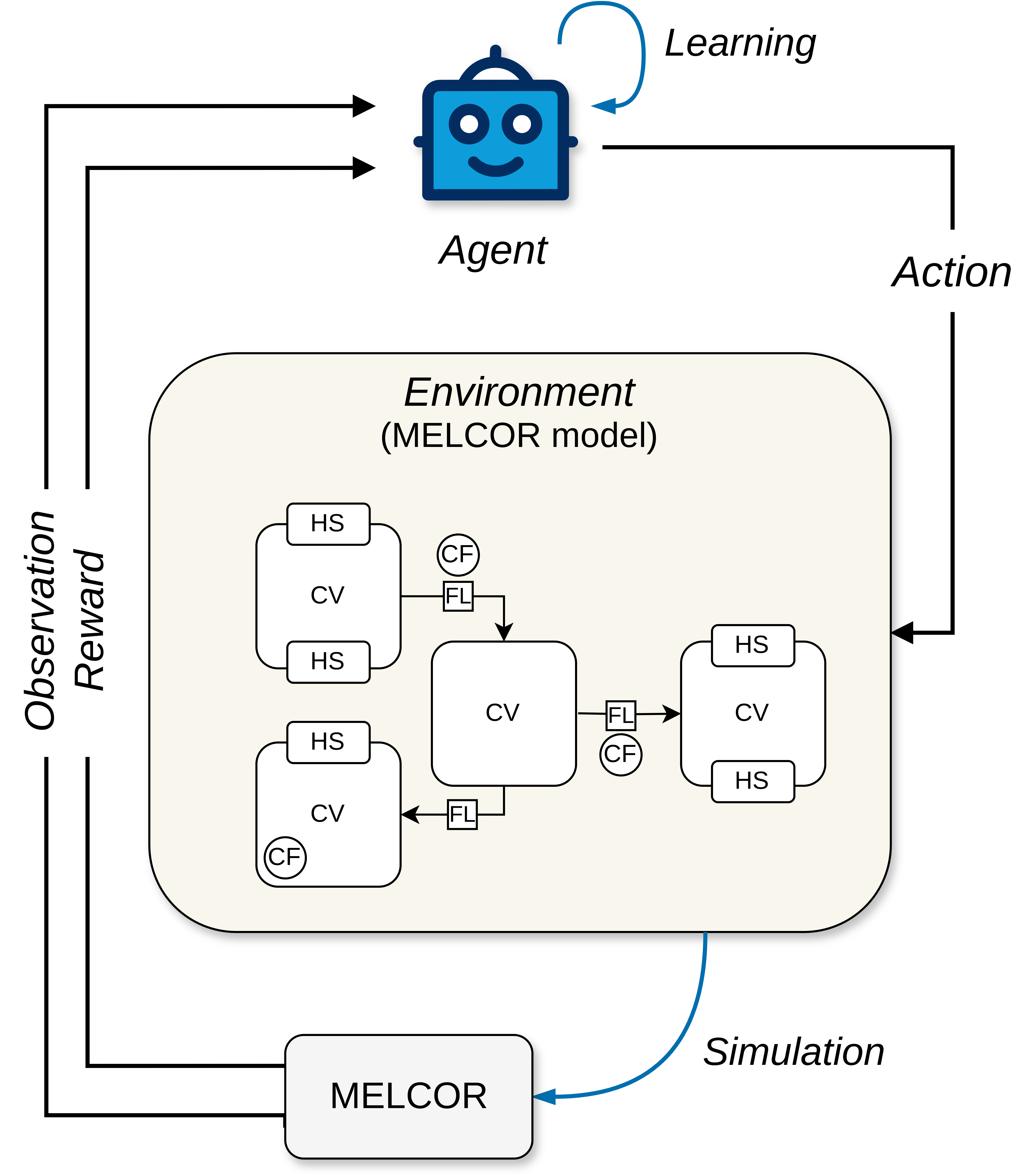
The Partially Observable Markov Decision Process implemented in MELGYM
At each time step \(t\), the agent receives an observation \(o_t \in \mathcal{O}\), representing a subset of variables that define the current state \(s_t \in \mathcal{S}\). Based on this observation, it selects an action \(a_t \in \mathcal{A}\), which modifies the MELCOR model. The simulation then proceeds, generating a new state \(s_{t+1}\) and a reward \(r_t \in \mathbb{R}\) that evaluates the outcome of the transition, thereby guiding the learning process.
The agent follows a policy function \(\pi\), such that \(a_t \sim \pi(\cdot|s_t)\). The goal is to find an optimal policy \(\pi^*\) that maximizes expected cumulative reward: \(G_t = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1}\), where \(\gamma \in [0,1]\) is a discount factor weighting future rewards.
When RL is combined with neural networks, it yields deep reinforcement learning (DRL). These methods employ parameterized policies \(\pi_\theta\)—such as neural networks with weights \(\theta\)—and use gradient-based optimization to approximate the optimal policy.
RL control in MELGYM
MELGYM enables the integration of DRL-based controllers into MELCOR simulations. This is achieved via the intermediate restarts described earlier.
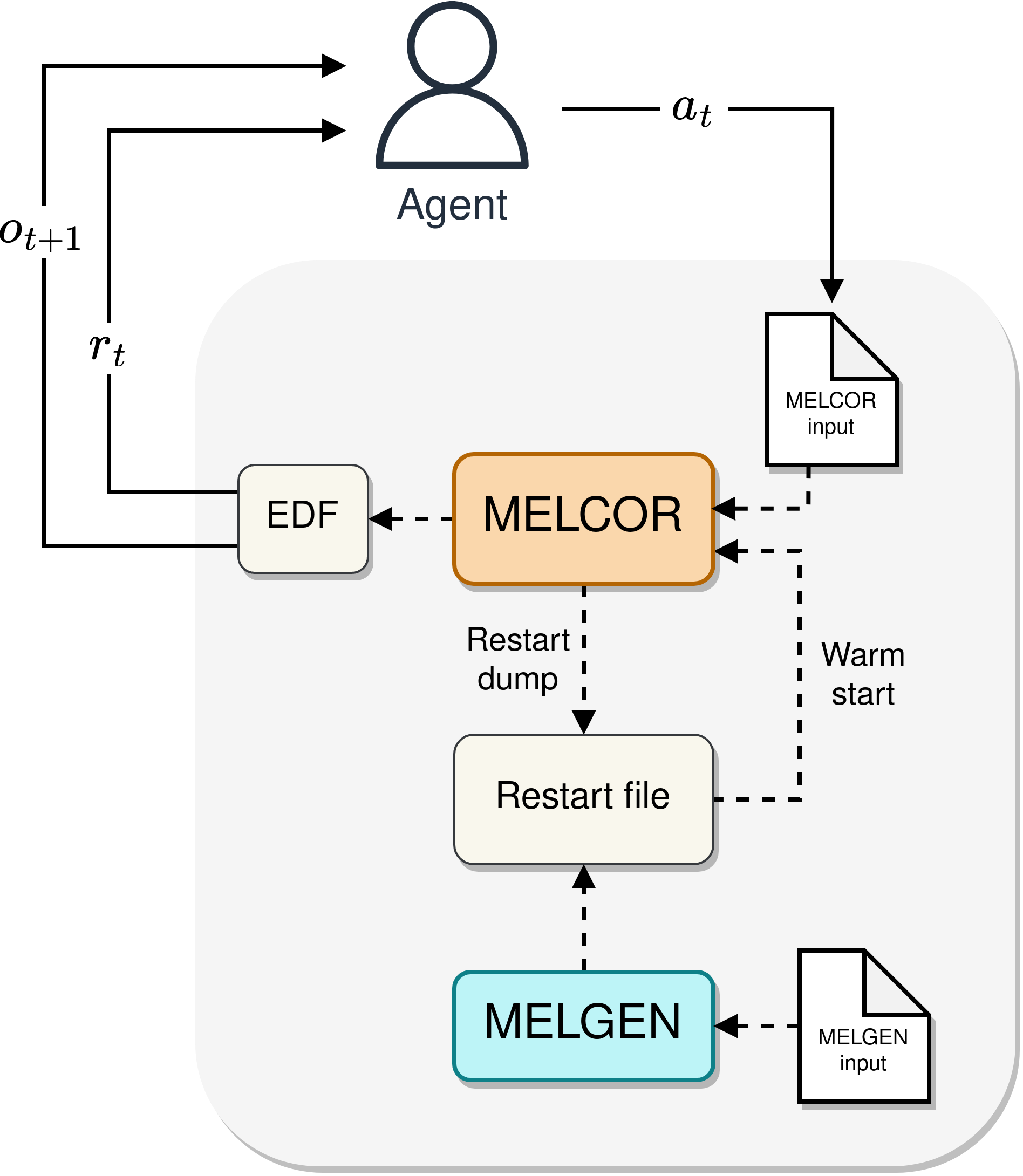
Agent-environment interaction loop
EDF outputs from MELCOR are parsed into observations used by the agent to determine the next control action and calculate the associated reward. Actions involve modifying control elements permitted by the MELGYM environment. The set of observed variables, available actions, and the reward and termination conditions are defined by each specific environment.
Note
MELGYM adheres to the standard Gymnasium interface, and its environments implement typical methods such as reset, step, and render. The agent implementation depends on user preferences. The Stable-Baselines3 library is a well-tested option that is highly recommended.
Tip
After this introduction, head to section Examples for a practical guide on using a DRL controller with MELGYM.